
RPC服务器不可用情况下的紧急应对措施与长期解决方案

一、引言
随着远程过程调用(RPC)在分布式系统中的应用越来越广泛,RPC服务器的稳定性问题也备受关注。
当RPC服务器出现不可用情况时,如何迅速应对并找到长期解决方案,成为确保系统正常运行的关键。
本文将详细介绍RPC服务器不可用时的紧急应对措施以及长期解决方案。
二、RPC服务器不可用的原因
在探讨解决方案之前,我们先来了解RPC服务器不可用的原因。常见的RPC服务器不可用原因包括:
1. 服务器硬件故障:如服务器宕机、内存不足等。
2. 网络问题:网络延迟、丢包或中断可能导致RPC调用失败。
3. 服务端软件故障:服务端程序崩溃、服务未启动等。
4. 负载均衡问题:在高并发情况下,可能导致部分服务器过载,从而影响服务可用性。
三、紧急应对措施
在RPC服务器不可用的情况下,我们可以采取以下紧急应对措施:
1. 故障诊断与定位:
(1)检查服务器状态:通过远程登录服务器,查看服务器日志、进程状态等,判断服务器是否正常运行。
(2)网络测试:使用工具如ping、traceroute等测试网络连通性,排查网络问题。
(3)负载均衡检查:检查负载均衡器的配置及运行状态,确保请求能够合理分配到各服务器节点。
2. 快速恢复服务:
(1)重启服务:尝试重启RPC服务,以解决可能的软件故障。
(2)扩容资源:在资源不足的情况下,临时增加服务器资源,如内存、CPU等。
(3)调整负载均衡策略:根据实时监控数据,调整负载均衡策略,避免服务器过载。
3. 备用服务切换:
(1)备用服务器:预先准备备用服务器,当主服务器出现故障时,可快速将流量切换到备用服务器。
(2)服务降级:在紧急情况下,可以暂时降级服务功能,以保证核心业务的正常运行。
四、长期解决方案
为了根治RPC服务器不可用的问题,我们需要从长期角度考虑解决方案。以下是一些建议:
1. 监控与预警系统:
(1)建立完善的监控体系:对服务器状态、网络状况、负载均衡等进行实时监控。
(2)设置预警阈值:根据业务需求和系统性能,设置合理的预警阈值,当达到阈值时,自动触发预警通知。
(3)自动化报警与恢复:通过自动化脚本或工具,实现故障报警后的自动恢复操作,减少人工干预。
2. 冗余设计与负载均衡:
(1)多副本部署:对关键服务进行多副本部署,提高服务的容错性。
(2)智能负载均衡:采用更智能的负载均衡策略,如基于业务特性的动态路由,以优化请求分配。
(3)服务网格:引入服务网格架构,提供强大的流量管理能力,包括路由、负载均衡、熔断等。
3. 性能优化与扩展性设计:
(1)性能优化:针对RPC框架、序列化方式等进行性能优化,提高处理能力和响应速度。
(2)水平扩展:设计系统时考虑水平扩展能力,以便在需要时增加更多的服务器节点。
(3)自动伸缩:结合云服务提供商的自动伸缩功能,根据性能指标自动调整服务器资源。
4. 持续优化与更新:
(1)定期评估系统性能:定期评估系统性能,识别瓶颈和改进点。
(2)跟进技术更新:关注最新技术动态,及时引入新技术以提高系统性能与稳定性。
(3)培训与意识提升:加强团队技术培训和意识提升,提高团队应对问题的能力。
五、总结
RPC服务器不可用是一个常见的问题,但我们可以采取紧急应对措施和长期解决方案来确保系统的稳定运行。
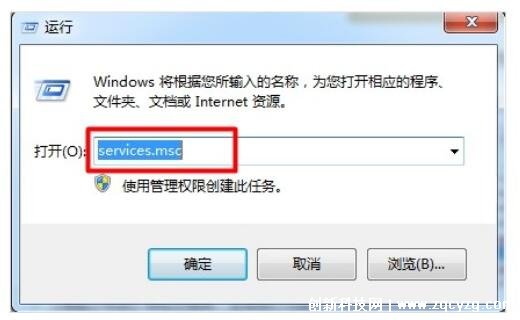
通过故障诊断与定位、快速恢复服务、备用服务切换等紧急措施,我们可以迅速应对故障。
而从长期角度来看,建立监控与预警系统、冗余设计与负载均衡、性能优化与扩展性设计以及持续优化与更新等方案,则可以根治问题并提高系统性能。